本文共 773 字,大约阅读时间需要 2 分钟。
昨日,,其中Facebook的断电时常更是超过10小时之久。对于宕机事件,Google和Facebook后续分别公开说明了原因。
Google此次中断时常持续约4个小时,影响了Gmail, G Suite, YouTube等产品。
Google在中断事故分析报告中表示,此次事故是 SRE 超载系统使得 Google 云存储错误率提高导致。
报告中说明,3 月 11 日,Google SRE 被告警内部 blob 服务使用的元数据的存储资源显著增加;为了减少资源使用,3 月 12 日SRE进行了配置更改,使系统的关键部分超载以查找 blob 数据的位置,最终导致级联故障。
此次事故中,重大的影响包括:Google 云存储的长尾延迟较高,平均错误率为 4.8%,所有存储桶位置和存储类都受到影响,依赖于云存储的 Google 云平台服务也受到影响;Stackdriver Monitoring 在检索历史时间序列数据时出现了高达 5% 的错误率,最近的时间序列数据可用,警报没有受到影响。App Engine 的 Blobstore API 出现了较高的延迟和错误率,在获取 blob 数据时达到峰值 21%,App Engine 部署出现了高达 90% 的错误,从 App Engine 提供静态文件也会出现错误率提升。
对于因此事件受到影响的服务与应用客户,谷歌“深表歉意”,并表示正在采取措施以提高可用性并防止此类中断再次发生。
昨日,不少猜测说Facebook宕机事故是由于路由泄露引起的,而Facebook官方披露的原因是服务器配置变更引起的。
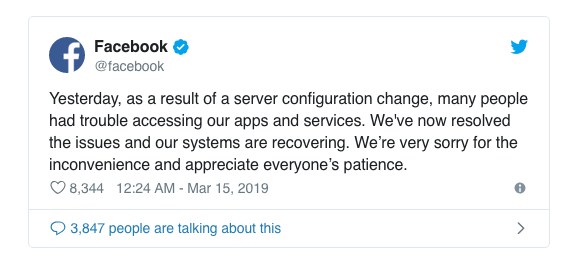
昨日,由于服务器配置变更,导致很多用户无法访问我们的应用和服务。现在我们已经解决了这个问题,系统已经恢复。对用户造成的不便我们深感歉意,感谢所有人的耐心。
转载地址:http://rwmix.baihongyu.com/